
解析库pyquery
初始化比如直接传入字符串,传入 URL,传入文件名,等等
像 Beautiful Soup 一样,初始化 pyquery 的时候,也需要传入 HTML 文本来初始化一个 PyQuery 对象
字符串初始化1234567891011121314from pyquery import PyQuery #导入PyQuery库html =\"""<div id="top"> <span class="position" width="350">职位名称</span> <span>职位类别</span> <li class="item-0"> <a href="link1.html">爬虫</a> </li></div> """ # 字符串doc = PyQuery(htm ...
后渗透阶段Windows系统提权
学习总结
系统权限分类Windowsnet user 用户名查看一下当前用户权限下面我有一个zhao的用户在Administrator组里面
1. user普通用户权限来宾权限他的无法更改系bai统属性和配置,只作来宾临时使用
2. Administrator超级管理员Administrator超级管理员都是他用的注册表和其他的文件是不能修改删除的 他可以修改一切user普通用户
3. system内核级账号system才算是windows系统里面的最高权限,但是system有的Administrator权限也是不能操作的下面是比如的权限管理范围
Linux1. user普通用户权限来宾权限他就是个普通权限的账号
2. root最高权限他是系统最高权限什么都可以做,就相当于win系统的Administrator加system
XP用at命令Administrator提权到systemwin7里面不能使用了
格式at 指定的时间 /interactive cmd
咧命令
下面命令的意思是在10:59启动一个cmd/interactive 是允许作业在运行时,与当时登录的用户桌面进 ...

5.php代码审计常见漏洞
笔记
代码审计SQL注入漏洞SQL注入的类型字符型注入是有单引号的咧
1SELECT * FROM users WHERE id='$id';
数字型注入是没有单引号的咧
1SELECT * FROM users WHERE id=$id;
这个前面博客有写
预防 addslashes()函数在每个双引号(”)前添加反斜杠 代码
123 <?php $a=$_GET['a'];echo addslashes($a);
代码审计宽字节注入及二次注入宽字节注入
字符、字符集与字符序字符( character)是组成字符集( character set)的基本单位。对字符赋予一个数值( encoding)来确定这个字符在谤字符集中的位置。字符序( collation)指同一字符集內字符间的比较规则。
UTF8由于AsC表示的字符只有128个,因此网络世界的规范是使用 UNICODE编码,但是用ASC表示的字符使用 UNICODE并不高效。因此出现了中间格式字符集,被称为通用转换格式,及UTF(Universal Transfor ...

lxml解析库用XPath语言提取数据
学习总结
书名《Python3 网络爬虫开发实战》
学习视频地址地址https://www.bilibili.com/video/BV1n7411m7BR
lxml解析是用c语音编写的他解析XPath语言所以他的解析速度
为什么要用到lxml解析库,我们在请求响应回来的数据他只是一个html的字符串,lxml就是把html或xml的字符串解析成html或xml的页面
lxml解析就是html/xml解析器
解析html/xml的页面html字符串解析我们在请求响应回来的数据他只是一个html的字符串,lxml就是把html或xml的字符串解析成html或xml的页面
lxml库有一个etree 模块下有一个html类,叫html的字符串进行初始化,构造一个 XPath 解析对象
代码
1234567891011121314151617from lxml import etree # 导入lxml库text = '''<div> <ul> <li class="item-0&q ...
解析库XPath的语法
学习总结
XPath( XML Path Language),他是在html和xml中查找信息的语言,他是通过标签属性来查询
谷歌安装XPath插件和说明名称XPath Helper
按Shift+鼠标上下可以调整位置
XPath语法
表达式
描述
//
查询的父标签,比如//div就是查询这个页面的全部是div的标签
/
查询的子标签,比如//div/span就会叫div标签下的span子标签
[@xxx]
指定标签里面属性来查询,比如//div[@class]就是查询div标签里面带class属性的
/@xxx
指定查询的属性内容,比如//a/img/@src 意思就是要a标签下的img里面的src属性的内容,可以用来提取照片
.
当前节点
..
选取当前节点的父节点
//查询的父标签比如我想查看他的上映日期,他的标签是span
那我语法就可以用//查询全部的的span标签里面的内容,
可以看见他会叫全部的span标签的全部的数据都显示出来了
/查询的子标签上面的//他是输出的是全部
我们就可以用/指定输出 ...

脚本编写实现简单登录爆破
我对代码创造方面想象力丰富,这是我最大的特点,下面我闲着没事就随便写了一个,非常简单的一个脚本
实验环境DVWA登录页面
手动测试他的登录机制可以用burp进行抓包查看他的请求和响应
下面这个是他的首次请求的内容,请求数据包
第二次请求的时候发现他都有Cookie了
发现这个Cookie是第一次请求的时候他返回给客户端的,说明是服务器给的Cookie,基本上都是服务器给的
手动登录查看一下请求,发现有一个给登录着的随机数,如果随机数不正确的话,肯定是登录不了的
找随机数的来源,发现他是上一次请求响应的时候服务器给的
脚步的编写获取登录的Cookie用python的会话维持,获得Cookie,不要会话维持就像两个浏览器访问一样到下次Cookie是不一样的
123456789101112import requests# 用`Session` 对象维持会话r=requests.session()# 用Session的get请求ask=r.get('http://192.168.84.58/login.php')# cookies方法输出获取请求后的cook ...
kali安装burpsuite pro破解版2021版
小学英语不过关的我用英文版burp是很费劲的,burp是没有中文版
burp专业版要399美元,穷比我肯定是买不起的
非常感谢的一个团队感谢他的付出burp汉化补丁https://github.com/funkyoummp/BurpSuiteCn/
linux系统burp进行破解可能比较繁琐
我在漏洞挖用的最多的就是burpsuite,手动漏洞挖机测试的最好的工具没有之一、
我之前一直用的是2.0.11版本这个版本也是用了好几年了,burp现在已经更新了好多版本了,什么都是用最新版本的软件好。
现在都2021.8.12了,肯定要用最新版的
破解方法其实全部的burp破解都是大同小异
安装启动环境
注册机
最新版burp
中文包
下载
burp最新版下载地址https://portswigger.net/burp/releases我下载的是最新版的2021.8版本
注册机下载地址https://github.com/h3110w0r1d-y/BurpLoaderKeygen
环境安装https://www.oracle.com/j ...

Xray安全评估工具
学习总结
xray是长亭科技的一款社区版漏洞扫描工具
他的github项目地址:https://github.com/chaitin/xray(不是源的项目)
官方使用文档:https://docs.xray.cool/#/
目前支持的漏洞检测类型包括:
XSS漏洞检测 (key: xss)
SQL 注入检测 (key: sqldet)
命令/代码注入检测 (key: cmd-injection)
目录枚举 (key: dirscan)
路径穿越检测 (key: path-traversal)
XML 实体注入检测 (key: xxe)
文件上传检测 (key: upload)
弱口令检测 (key: brute-force)
jsonp 检测 (key: jsonp)
ssrf 检测 (key: ssrf)
基线检查 (key: baseline)
任意跳转检测 (key: redirect)
CRLF 注入 (key: crlf-injection)
Struts2 系列漏洞检测 (高级版,key: struts)
Thinkphp系列漏洞检测 (高级版,key: thinkp ...
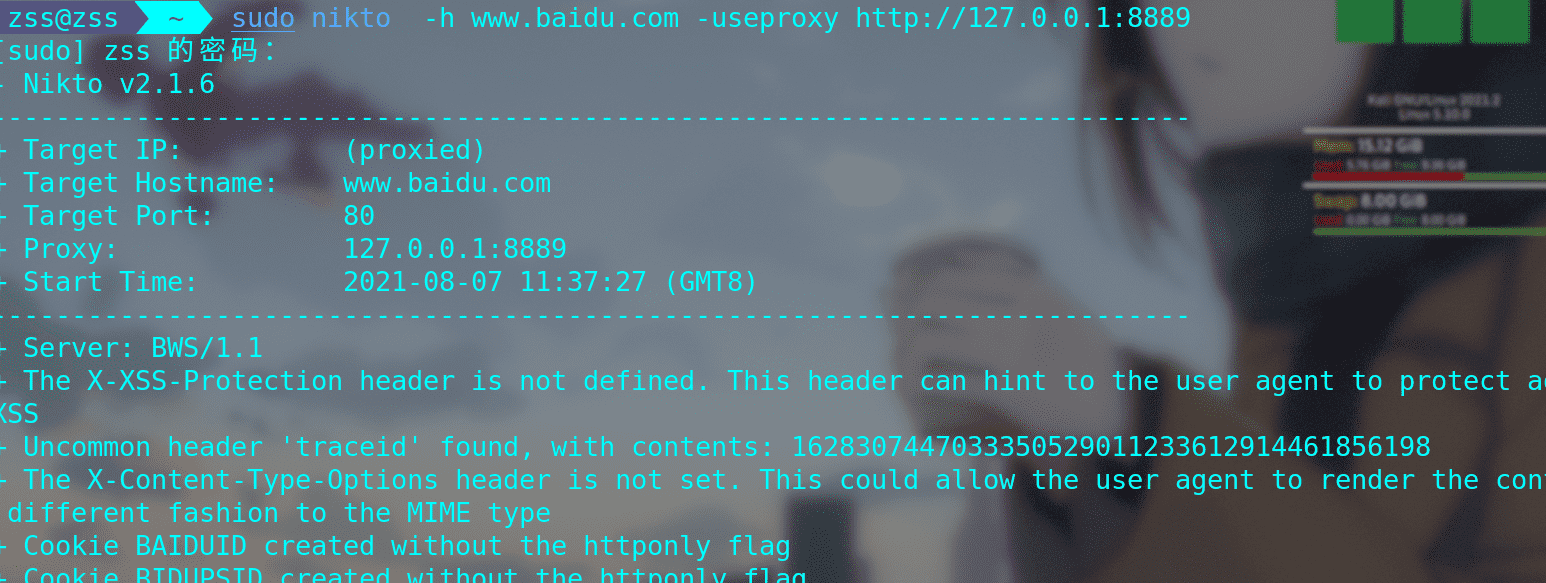
nikto web服务器扫描器工具
记录笔记
官方工具的使用
nikto工具安装kali默认是安装了的
其他linux的安装方法很简单
克隆github
1git clone https://github.com/sullo/nikto
proxychains4是我添加了代理
进入目录cd nikto/program
运行./nikto.pl
nikto工具的使用全部参数
选项
描述
-ask
是否询问提交更新: yes - 询问每个(默认) *no - 不询问,不发送 *auto - 不询问,只发送
-Cgidirs
扫描这些 CGI 目录: * none * all * 或类似 “/cgi/ /cgi-a/“ 的值
-config
使用这个配置文件
-Display
打开/关闭显示输出:
1 显示重定向
2 显示收到的 cookie
3 显示所有 200/OK 响应
4 显示需要身份验证的 URL * D 调试输出 * E 显示所有 HTTP 错误 * P 打印进度到 STDOUT * S Scrub IP 和主机名的 输出 * V 详细输出
...
网站搭建,搜索引擎收录,利用网站创收赚钱相关问题
我在网站方面在前几年到现在一直在学习,大部分还是在学习后端,学习web漏洞挖机必须要学习网站开发的基本知识,特别是后端的开发,在做代码审计的时候必须要有一定的后端编程功底,至于前端开发相比编程来说已经是很简单的了,学习过前端的基础知识,但是前端我用的比较少只能说我是个半吊子
搭建网站进行魔改和的添加加速收录等等内容比较多,写半个书都不够,你不懂得还是问谷歌百度吧
搭建问题我这个是用的是hexo框架和github托管+腾讯CDN+自己域名
域名备案域名备案是感觉是比较麻烦的填写的东西非常多,应为照片的问题两个多月才完成,阿里那边会给你打电话问一些情况
通过网站下面的备案号是可以在这个网站查到到https://beian.miit.gov.cn/#/Integrated/index
